阅读redis代码(二)—— Dict字典和哈希算法
Updated:
字典是一种用来保存键值对(key-value)的抽象数据结构。redis中, 数据库底层就是用字典实现的,包括对数据库的增,删,改,查。
比如上一篇文章提过的例子:
Redis将在数据库中创建了一个新的键值对,这个键值对就是字典来实现的。
除此之外,字典还是哈希键的底层实现之一: 当一个哈希键包含的键值对比较多, 又或者键值对中的元素都是比较长的字符串时, Redis 就会使用字典作为哈希键的底层实现。Redis 中每个 hash 可以存储 2e32 - 1 键值对(40多亿)。
哈希算法
什么是哈希算法?哈希是hash(散列)的谐音,所以哈希算法也叫散列算法。一般来说满足这样的关系:f(data)=key,输入任意长度的data数据,经过哈希算法处理后输出一个定长的数据key。同时这个过程是不可逆的,无法由key逆推出data。
如果是一个data数据集,经过哈希算法处理后得到key的数据集,然后将keys与原始数据进行一一映射就得到了一个哈希表。哈希表在对于原始数据比较大的时候很有好处。当原始数据较大时,我们可以用哈希算法处理得到定长的哈希值key,那么这个key相对原始数据要小得多。我们就可以用这个较小的数据集来做索引,达到快速查找的目的。
比如这里有一万首歌,要求按照某种方式保存好。到时候给你一首新的歌(命名为X),要求你确认新的这首歌是否在那一万首歌之内。无疑,将一万首歌一个一个比对非常慢。但如果存在一种方式,能将一万首歌的每一首的数据浓缩到一个数字(称为哈希码)中,于是得到一万个数字,那么用同样的算法计算新的歌X的编码,看看歌X的编码是否在之前那一万个数字中,就能知道歌X是否在那一万首歌中。
再稍微思考一下就可以发现,既然输入数据不定长,而输出的哈希值却是固定长度的,这意味着哈希值是一个有限集合,而输入数据则可以是无穷多个。那么建立一对一关系明显是不现实的。当有两个或以上数量的键被分配到了哈希表数组的同一个索引上面时, 我们称这些键发生了冲突(collision)。所以”冲突”是必然会发生的,所以一个成熟的哈希算法会有较好的抗冲突性。同时在实现哈希表的结构时也要考虑到哈希冲突的问题。
redis中字典的实现
在redis中的字典是由哈希表来实现的。
redis中的哈希表就是存放有很多哈希节点的表结构,一个哈希节点就保存了字典中的键值对。因此从上而下的结构关系是:
字典 –> 哈希表 –> 哈希节点 –> 字典的键值对
那么就从代码中一一分析一下这三者的数据结构。
字典
Redis 中的字典由 dict.h/dict 结构表示:
字典的属性成员有:
type: 这是一个指针,指向dictType结构,每个 dictType 结构保存了一簇用于操作特定类型键值对的函数, Redis 会为用途不同的字典设置不同的类型特定函数。我们后面会用到到hashFunction这个函数。
12345678typedef struct dictType {uint64_t (*hashFunction)(const void *key);void *(*keyDup)(void *privdata, const void *key);void *(*valDup)(void *privdata, const void *obj);int (*keyCompare)(void *privdata, const void *key1, const void *key2);void (*keyDestructor)(void *privdata, void *key);void (*valDestructor)(void *privdata, void *obj);} dictType;private:私有数据,保存了需要传给类型函数的参数。
- ht[2]: 哈希表,每个字典有两个哈希表, 一般情况下, 字典只使用 ht[0] 哈希表, ht[1] 哈希表只会在对 ht[0] 哈希表进行 rehash 时使用。
- rehashidx: rehash索引,当rehashidx==-1的时候,说明不在进行rehash。
- iterators: 记录当前的迭代次数
哈希表
哈希表的数据结构定义在dict.h中的dictht:
哈希表的结构体属性成员有:
- **table: 哈希表数组,数组中的每个元素都是一个指向 dict.h/dictEntry 结构的指针, 每个 dictEntry 结构保存着一个键值对
- size:哈希表大小
- sizemask: 哈希表大小的掩码表示,总是等于size-1,这个属性和哈希值一起决定一个键应该被放到 table 数组的哪个索引上面
- used: 表示已经使用的节点数量
哈希表节点
哈希表节点使用 dictEntry 结构表示, 每个 dictEntry 结构都保存着一个键值对。
从代码可以看出,有key属性,保存着键,而v的共用体(union)保存键的值,可以是指针,也可以是uint64_t,int64_t整数,也可以是double值。
除此之外,还有next指针,指向下一个哈希表节点。这个指针可以将多个哈希值相同的键值对连接在一次, 以此来解决键冲突(collision)的问题。
如下图所示是一个完整的字典,这个字典是处于普通状态(没有进行rehash)
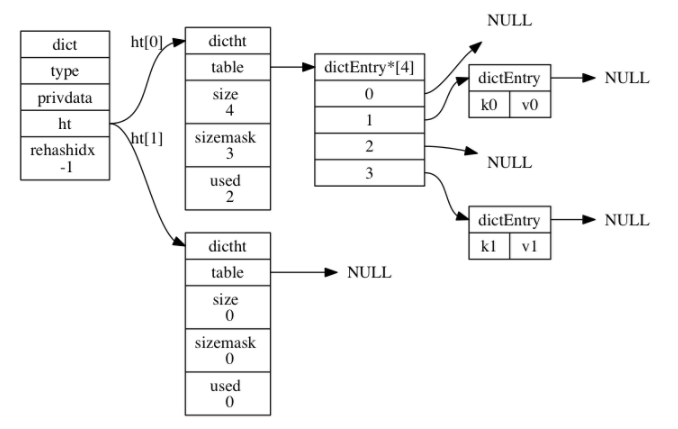
redis中的哈希算法
redis中当新建一个新的键值对(key-value pair)添加到字典中时,程序会根据键值对的key计算出哈希值和索引值,然后再根据索引值,将包含新建的键值对的哈希节点添加到哈希表中的指定索引位置上。
|
|
我们可以看一下实际的调用,当创建redis的database时,会调用dbDictType的指针,上面我们提到过,每个 dictType 结构保存了一簇用于操作特定类型键值对的函数。
于是我们找到dbDictType的实例化不同的操作函数。关注第一个hashFunction的定义是dictSdsHash函数,这个函数实际调用dictGenHashFunction函数,这个通用哈希函数最终计算出一个哈希值。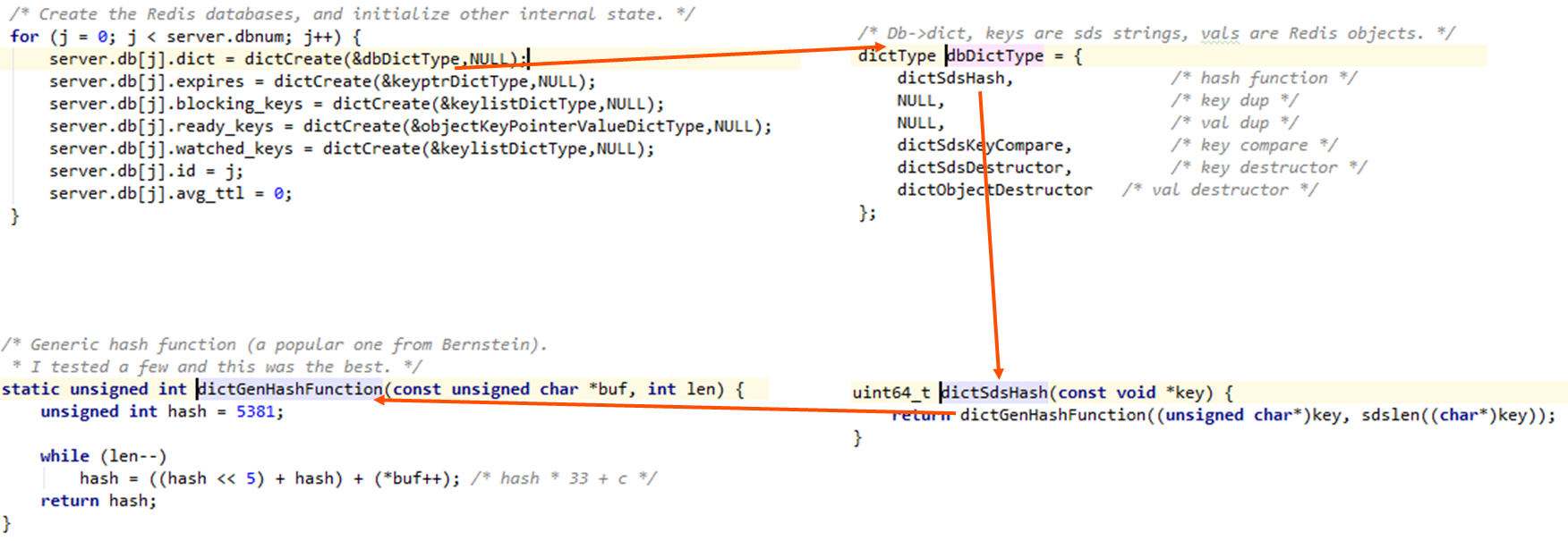
举个例子,假设我们要往一个如下图所示的空字典中新增一个键值对。size为4,sizemask为4-1=3。
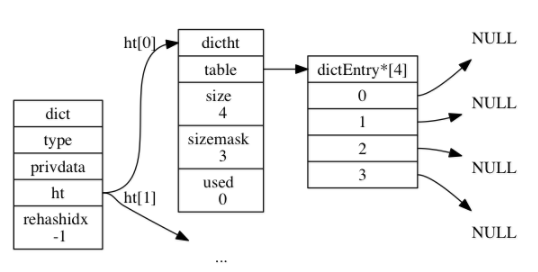
hashFunction是dict中type的定义函数,因此如果要新增一个key-value,比如k0:v0到字典中去的时候,程序会做这样一些操作:
计算k0的哈希值:
1hash = dict->type->hashFunction(k0)上一步得到哈希值假设为8,继续来计算index索引值:
1index = hash & dict->ht[0].sizemask;这时得到的index为
8&3=0。因此这个键值对会被放置到哈希数组列表的索引0上。
操作后的字典如下图所示,并且看到used的值变为1: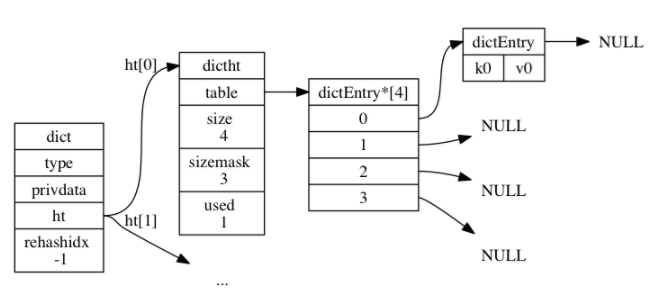
redis的rehash
随着操作的不断执行, 哈希表保存的键值对会逐渐地增多或者减少, 为了让哈希表的负载因子(load factor)维持在一个合理的范围之内, 当哈希表保存的键值对数量太多或者太少时, 程序需要对哈希表的大小进行相应的扩展或者收缩。
扩展和收缩哈希表的工作可以通过执行 rehash (重新散列)操作来完成, Redis 对字典的哈希表执行 rehash 的步骤如下:
- 为字典的
ht[1]哈希表分配空间, 这个哈希表的空间大小取决于要执行的操作, 以及ht[0]当前包含的键值对数量 (也即是ht[0].used属性的值):- 如果执行的是扩展操作, 那么
ht[1]的大小为第一个大于等于ht[0].used * 2的2^n(2 的 n 次方幂); - 如果执行的是收缩操作, 那么
ht[1]的大小为第一个大于等于ht[0].used的2^n。
- 如果执行的是扩展操作, 那么
- 将保存在
ht[0]中的所有键值对 rehash 到ht[1]上面: rehash 指的是重新计算键的哈希值和索引值, 然后将键值对放置到ht[1]哈希表的指定位置上。 - 当
ht[0]包含的所有键值对都迁移到了ht[1]之后 (ht[0]变为空表), 释放ht[0],将 ht[1]设置为ht[0], 并在ht[1]新创建一个空白哈希表, 为下一次 rehash 做准备。12345678910111213141516171819202122232425262728293031323334353637383940414243444546int dictRehash(dict *d, int n) {int empty_visits = n*10; /* Max number of empty buckets to visit. */if (!dictIsRehashing(d)) return 0;//while(n-- && d->ht[0].used != 0) {dictEntry *de, *nextde;/* Note that rehashidx can't overflow as we are sure there are more* elements because ht[0].used != 0 */assert(d->ht[0].size > (unsigned long)d->rehashidx);while(d->ht[0].table[d->rehashidx] == NULL) {d->rehashidx++;if (--empty_visits == 0) return 1;}de = d->ht[0].table[d->rehashidx];/* Move all the keys in this bucket from the old to the new hash HT */while(de) {unsigned int h;nextde = de->next;/* 得到新的哈希表中的索引值,然后把ht[0]的节点按照索引值放置到ht[1]中*/h = dictHashKey(d, de->key) & d->ht[1].sizemask;de->next = d->ht[1].table[h];d->ht[1].table[h] = de;d->ht[0].used--;d->ht[1].used++;de = nextde;}d->ht[0].table[d->rehashidx] = NULL;d->rehashidx++;}/* Check if we already rehashed the whole table... *///如果已经把ht[0]中的值全部散列到ht[1]完毕,再把ht[1]赋值给ht[0],再把ht[1]清空if (d->ht[0].used == 0) {zfree(d->ht[0].table);d->ht[0] = d->ht[1];_dictReset(&d->ht[1]);d->rehashidx = -1;return 0;}/* More to rehash... */return 1;}
参考文献
《redis设计与实现》