云环境上的OvS-DPDK VS OvS的Deep Dive
Updated:
背景
OvS(Open vSwitch)是云计算平台的重要连接组件,为虚拟机提供网络连,被各大云平台,基础设施供应商广泛使用,比如OpenStack, OpenNebula。vSwitch–Virtual Switch(虚拟交换机),在云环境中扮演交换机的角色,连接VM之间、VM与物理机之间的通讯。
互联网发展风起云涌,行业对网络速率的要求也是直线上升:10G -> 40G -> 100G… 传统的OvS因为性能限制很难跟上脚步。基于这个背景,Intel发布了开源项目DPDK,DPDK可以加速OvS性能,可以让内核OvS的性能提升8~9倍。那么,为什么DPDK可以大幅提升OvS的性能呢?接下来的文章中会对网卡虚拟化各代演化的设计进行剥丝抽茧地分析,探究性能是如何一步一步地提高。
典型应用场景
在云平台数据中心中一个典型的应用场景如下: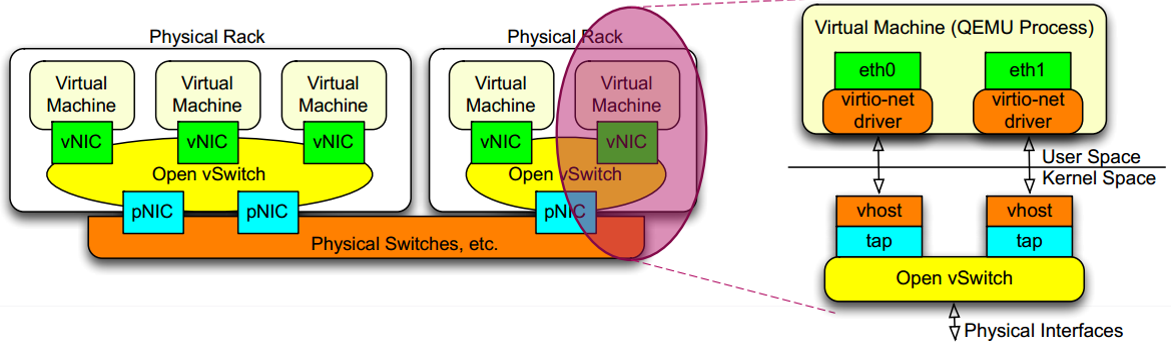
对于这个场景有两个通信路径:
- VM -> vNic -> OvS -> vNic -> VM (VM in the same host)
- VM -> vNic -> OvS -> pNic -> OvS -> vNic -> VM(different hosts)
第一个路径是同一台host主机上的VM之间的互相通信,第二个则是不同主机上的VM的通信路径,第二个路径也包含了外部主机访问虚拟机的路径。
网络开销
那么在这样的云环境下网络性能的瓶颈在哪里?
在传统的内核协议栈中,当有新的数据包到来时,网卡会通过硬件中断通知协议栈,内核的网卡驱动负责处理这个硬件的中断,将数据包从网卡拷贝到内核开辟的缓冲区中,所以协议栈的主要处理开销分为中断处理,内存拷贝,系统调用和协议处理4个方面。
- 硬件中断:反复中断用户态内核态的上下文切换和软中断都会大大增加额外的开销,并且中断处理程序应尽可能少,只是简单地通过PIO(Programming Input/Output Model)或DMA(DirectMemory Access)等方式协调后把数据包从网卡内存复制到内核开辟的缓冲区中。
- 内存拷贝:数据先从网卡缓存区通过PIO或DMA方式传送到内核开辟的缓冲区中,然后还要通过socket从内核空间复制到用户空间,统计表明,在Linux协议栈中,数据包从内核态拷贝到用户态所用的时间甚至占到了数据包整个处理流程时间的57.1%。
- 系统调用:系统调用是内核态向用户态提供的一组API集,系统调用一般通过软中断来实现,会产生较大的上下文切换开销。
- 协议处理:主要的耗时包括校验、计算、定时器管理、IP分片/重组、PCB连接管理、可靠传输机制和拥塞控制。
当千兆万兆网络出现后,网络数据包的协议处理占据着大量的CPU计算能力,网络协议栈的处理能力容易成为系统总体性能的瓶颈。传统的协议栈是针对通用性设计的,由于在内核实现,应用程序无法直接访问协议栈的地址空间,协议栈的安全性较高。
在用户空间层上实现TCP/IP协议栈,选择绕过内核使我们可以采用某些高级的捕获数据包技术(如直接写TAP字符设备或使用Libpcap捕包技术,或性能更高得多的零拷贝捕包技术,这些由于同在用户态中具有相同的特权指令级别,所以在user_buffer和nic_buffer之间可以直接做内存映射,例如virtio application)直接在网卡和用户空间形成通道,减少内存的复制次数。同时,可以按照自己的需求定制协议栈的协议处理流程,简化某些冗余的处理机制,因此,用户态协议栈的可定制性和可扩展性都比内核态协议栈要高。Openonload是Solarflare公司开发的一个专用高性能用户态协议栈,它运行在Linux上,并具有标准的BSD socket API接口,结合该公司开发的专用网卡设备及设备驱动程序,网络数据包得以旁路内核态协议栈,高效地到达用户态协议栈。
在多核CPU硬件结构中,要充分发挥计算能力,必须采用多进程执行,使得同一时刻都有一个线程(用户线程,内核线程,硬件线程)运行在一个CPU核上。
对于用户态协议栈的构建,可以分为两种模式:一种是用户程序与协议栈分别作为独立的进程,互相之间通过IPC通信;另一种方式是将用户程序和协议栈作为一个进程空间的两个现成实现,假如选择系统开销更小的线程来实现的话,用户态无法像在内核态一样使用中断来进行驱动,用户态的协议栈的数据来源也两种(网络数据包和socket请求),它们本质上都可以看成是消息,因此,用户态的驱动机制可以成为消息驱动机制。
对于基于传统的全虚拟化网卡技术+传统的Hypervisor+传统的Linux内核技术实现云环境,其中一个虚拟机到物理网卡会存在如下的性能开销:
- VM,在基于传统的Hypervisor技术中VM是宿主机用户空间的一个进程。在Linux中,一般使用TAP设备作为虚拟网卡,TAP设备在用户空间会有一个字符设备供虚拟机进程读写。
- Hypervisor层横跨用户空间和内核空间,这中间会存在数据在内核空间和用户空间的拷贝及切换。
内核网桥再访问物理网卡。
网络/IO虚拟化技术的演变
QEMU全虚拟化
传统全虚拟化网卡技术下的数据包从VM到物理网卡的路径如下图:
传统的KVM实现中,kvm.ko是内核的一个模块,主要用来捕获虚机的是上述的针对CPU、内存MMU的特权指令然后负责模拟,对I/O的模拟则是再通过用户态的Qemu进程模拟的,Qemu负责解释I/O指令流,并通过系统调用让Host操作系统上的驱动去完成真正的I/O操作。这其中用户态与内核态切换了2次,数据也需要复制2次。如下图所示: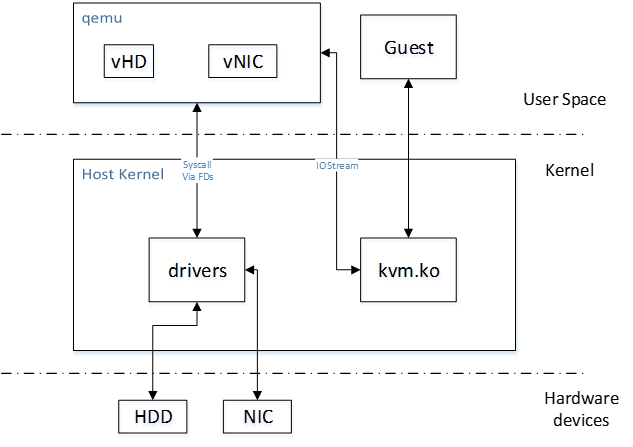
用户态的Qemu在启动Guest操作系统时,可以先通过KVM在用户态的字符接口/dev/kvm获取Guest的地址空间(fd_vm)和KVM本身(fd_kvm),然后通过fd_vm将Guest的物理空间mmap到Qemu进程的虚拟空间(虚机就是一个进程,虚机进程的用户虚拟空间就是Guest的物理空间,映射之后Qemu的虚拟设备就可以很方便的存取Guest地址空间里的数据了),并根据配置信息创建vcpu[N]线程(对虚机来说,虚机进程的线程对应着Guest的处理器),然后Qemu将操作fd_vcpu[N]在自己的进程空间mmap一块KVM的数据结构区域(即下图的shared,包括:Guest的IO信息,如端口号,读写方向,内存地址)。该数据结构用于Qemu和kvm.ko交互,Qemu通过它调用虚拟设备注册的回调函数来模拟设备的行为,并将Guest IO的请求换成系统请求发给Host系统。
全虚拟化网卡不需要改动虚拟机操作系统,Hypervisor层直接通过软件模拟实现一些通用操作系统都支持的常用网络驱动,如e1000、intel82545的等。这种通用性好一些,但性能不高。
virtio
为了提高全虚拟化网卡的效率,有人提出了用半虚拟化驱动程序——virtio。使用virtio就必须要在宿主机和虚拟机中同时安装virtio驱动,这样虚拟化的I/O就可以用标准的virtio标准接口来进行,虚拟化引擎也不用捕捉解释这些I/O请求了,可以大大提高性能。
其思想是宿主机和虚拟机操作系统同时改动配合提升性能,其架构如图4所示,前端驱动(如virtio_pci,virtio_net等)存在于虚拟机中(所以虚拟机操作系统 要改动和安装virtio专用驱动,Linux kernel从2.6.24开始支持virtio,Window虚拟机需要额外安装virtio的Window版驱动即可),后端驱动virtio backend存在于QEMU内核模块中(所以宿主机操作系统也要改动),中间的virtio是队列,virtio-ring是共享的环形缓冲区。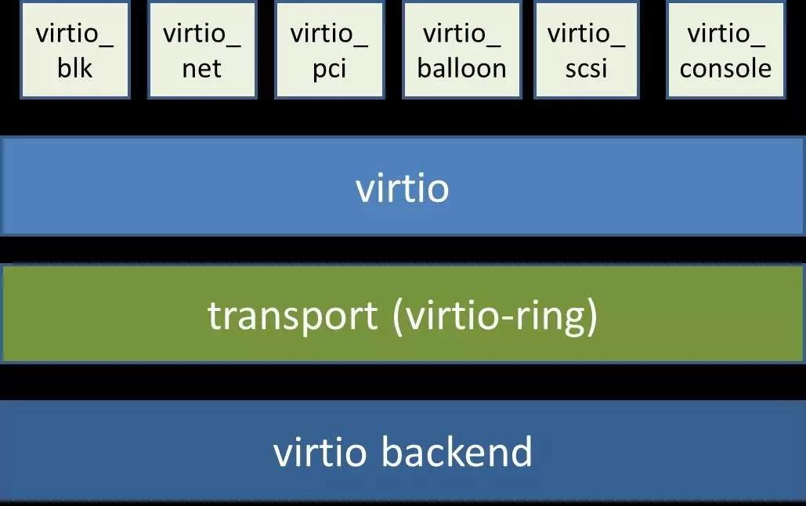
virtio通过共享内存的方式为Guest和Qemu提供了高速的硬盘与网络I/O通道(因为Guest的地址空间mmap到Qemu的进程空间)。Virtio只需要增加Virtio Driver和Virtio Device即可直接读写共享内存。如下图,Guest Virtio驱动通过访问port地址空间向Qemu的Virtio设备发送IO发起消息。而设备通过读写irqfd或者IOCTL fd_vm将I/O的完成情况通知给Guest的驱动。irqfd和ioeventfd是KVM为用户程序基于内核eventfd机制提供的通知机制,以实现异步的IO处理(这样发起IO请求的vcpu将不会阻塞)。之所以使用PIO而不是MMIO,是因为KVM处理PIO的速度快于MMIO(Memory mapping I/O)。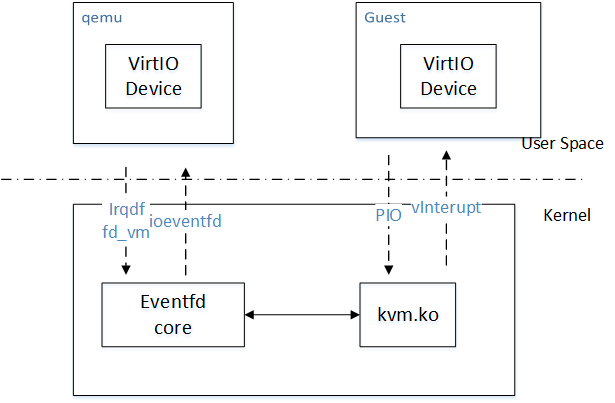
virtio的网络数据流如图6所示,其网络性能仍存在两个瓶颈:
- 用户态的guset进程通过virtio driver(virtio_net)访问内核态的KVM模块(KVM.ko),需要用户态和内核态切换一次,数据在用户态和内核态之间拷贝一次。
- 内核态的KVM.ko并不能直接访问同在内核态的TAP设备,先需要一次从内核态到用户态的切换,再通过用户态的QEMU进程在去访问TAP设备在用户态的字符设备接口,又得切换一次和进行一次数据拷贝。
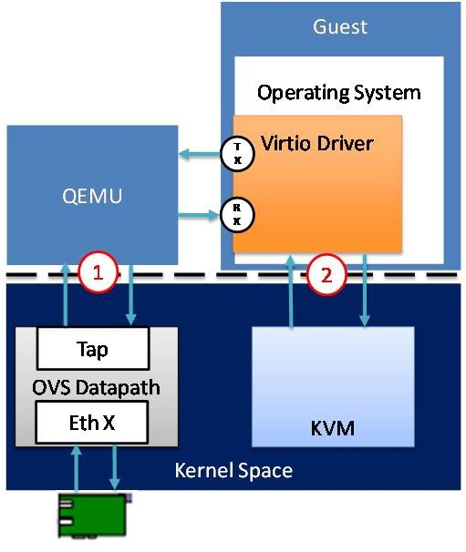
图6
vhoust-net
virtio通过共享内存减少了Guest与Qemu之间的复制数据的开销,有没有可能再优化一下?观察到virtio依然存在Qemu到内核的系统调用,可以将模拟I/O的逻辑VirtIO Device也挪到内核空间,避免Qemu和内核空间的系统调用。
vhost在内核态再增加一个vhost-net.ko模块, vhost client与vhost backend通过共享内存(virtqueues, unit socket), 文件描述符(ioeventfds),(中断号)irqfds实现快速交换数据的机制。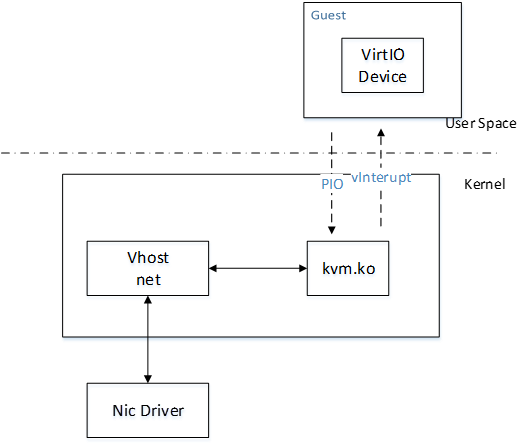
vhost的架构如图8所示,vhost实际上是两个进程之间通过共享内存实现通信的机制,它不仅可以在两个进程之间共享内存,还能通过unix socket在两个进程之间传递共享内存的文件描述符(ioevenfds)和中断号(irqfd),这样实现了两个进程之间的零拷贝(Zero Copy)。我们知道,在virtio架构中,虚拟网卡的数据缓冲区就是virtio-ring,通过vhost机制实现了数据的零拷贝。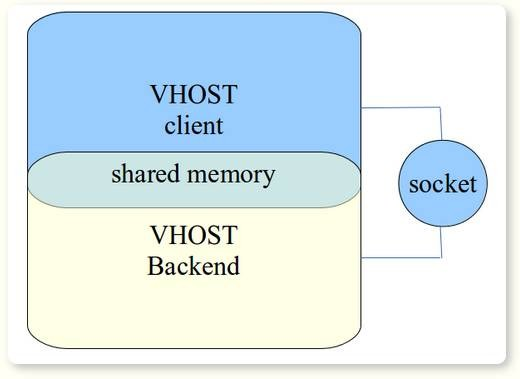
vhost的网络数据流如图9所示,在内核态增加了一个vhost驱动,与virtio相比,只需要进行一次用户态内核态切换(因为内核态的vhost-net.ko可以直接访问内核态的TAP设备,少了一次切换),另外,由于引入vhost技术共享了虚拟机的网卡缓冲区也省了一次数据拷贝(vhost-net.ko充当vhost backend,kvm.ko充当vhost client)。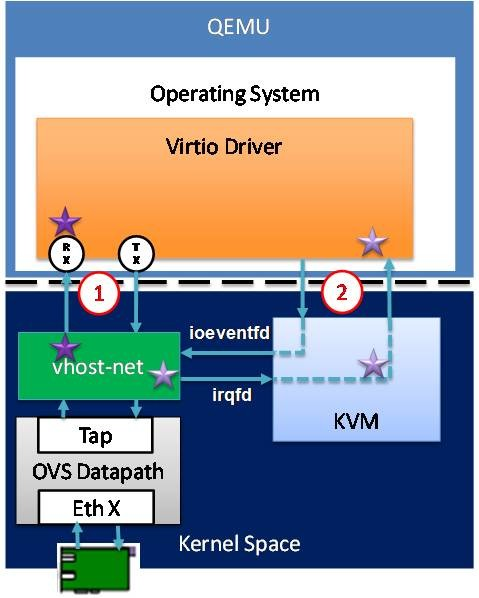
vhost-user
vhost比virtio减少了一次切换和拷贝,那么还有没有可能优化,比如实现零切换和零拷贝?
接着vhost-user就被提出,如下图所示,将驱动挪到用户态,不走kernel,以实现零切换和零拷贝。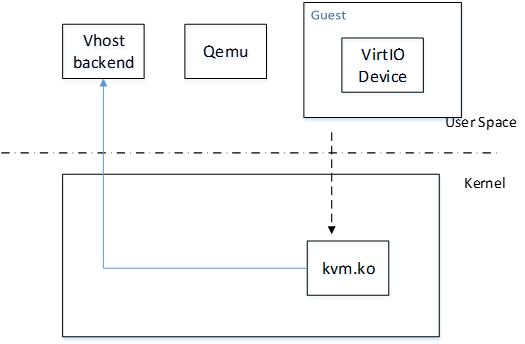
vhost-user是qemu 2.1版本引入的新特性,使用方式如下:
vhost是一种用户空间进程(vhost client与vhost backend)通过共享内存(virtqueues, unit socket), 文件描述符(ioeventfds), (中断号)irqfds实现快速交换数据的机制。vhost backend是一个userspace virtioapplication, 它能绕开kernel,和同样是usersapce的VM虚机进程直接通过共享内存实现zero-copy大大地提升性能;另一方面,kernel也会基于vhost技术为每个vring设备分配独立的中断号、事件中断、文件描述符等,并将这些通过unix socket传给其他用户空间进程,这样vhost backend并能直接访问虚机网卡的文件描述符。
一些实现了vhost backend的交换机(如snabbswitch)直接在用户态从vhost共享的虚拟机网卡缓存区virtio-ring中把网络数据进行读取,然后snabbswtich又实现了SR-IOV的物理网卡驱动直接将读到的虚拟机网络数据送到物理网卡上,从而大大提升了性能。所以基于vhost-user或者snabbswtich的技术甚至连虚拟网卡TAP设备都省了。snabbswitch是类似于Openvswitch的虚拟交换机,区别在于snabbswitch更重视性能。首先它是一个基于vhost-user的虚拟交换机应用,具有零拷贝和不走内核的特点;其次它实现了物理网卡驱动(目前只实现了一种驱动即intel10g.lua,支持Intel 82599 10-Gigabit芯片网卡)直接调用SR-IOV的硬件网卡的Tagging,Security等功能将由Neutron软件实现的改由硬件实现。基于这两个特点,snabbswitch的性能相当高。
DPDK(Data Plane Development Kit)
上文聊了很多,我们可以知道vhost-user的架构性能最好。Intel针对X86架构如何快速处理数据包开源了DPDK。DPDK是一个在用户态可以直接操作物理网卡的库函数,它和vhost-user结合便可以实现类似于snabb switch一样性能强劲的用户态交换机了。2015年6月16日dpdk vhost-user ports特性合并到了ovs社区。
DPDK特性有:
- 参考传统NP、多核处理器报文收发处理架构;
- X86架构上纯用户态驱动;
- R2C( run to completion )模型;
- 内存资源预先分配:Buffer/队列资源;基于mempool机制、 mbuf机制 环形队列:无锁设计 巨页机制:物理空间连续
- Executionunits:不支持调度。类似deadloop方式(可绑定逻辑核);
- PMD驱动,通过DMA实现零拷贝,不使用中断;
- 支持Intel 1G/10G网卡;部分非Intel网卡支持;VIRTIO/VMWARENET3半虚拟化网卡。
- 硬件网卡多队列、分类、QoS及卸载功能;
- 支持非虚拟化、虚拟化场景。
OVS DPDK架构
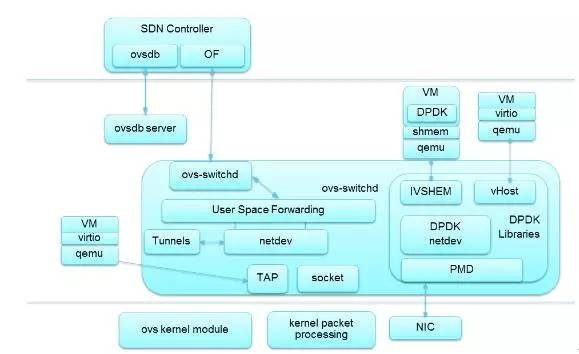
- 支持轻量型协议栈;
- 兼容virtio,vhost-net和基于DPDK的vhost-user加速技术;
- 支持Vxlan功能、端口Bonding功能;
- 支持OpenFlow1.0&1.3;
- 支持Meter功能、镜像功能;
- 支持VM热迁移功能;
- 性能较内核OVS可提升8~9倍。
OvS, OvS-DPDK I/O比较
对传统的OvS,依然需要在kernel态和用户态进行切换,data path如下图所示:
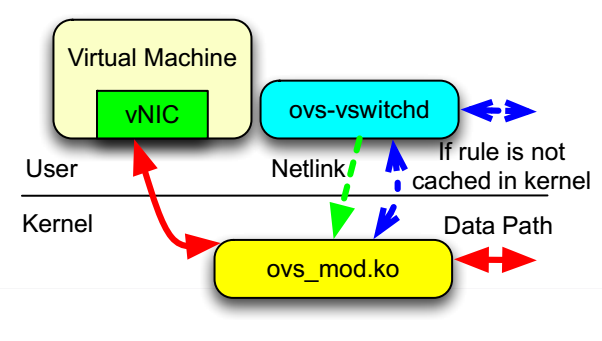
图12 而结合了DPDK的OvS的data path如下图所示:
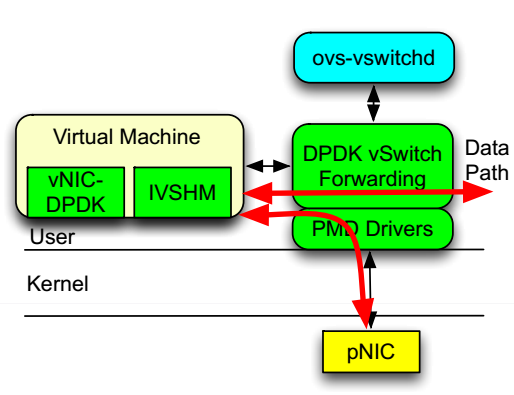
图13
在2016年的美国DPDK summit中发表了DPDK OVS相对于OVS的性能测评。他通过了4种不同的场景,综合地从throughput, IPC, Cache behavior等,可以帮助我们更好地理解OvS-DPDK在性能上的优势。摘取了几个结果,有兴趣的同学可以看看。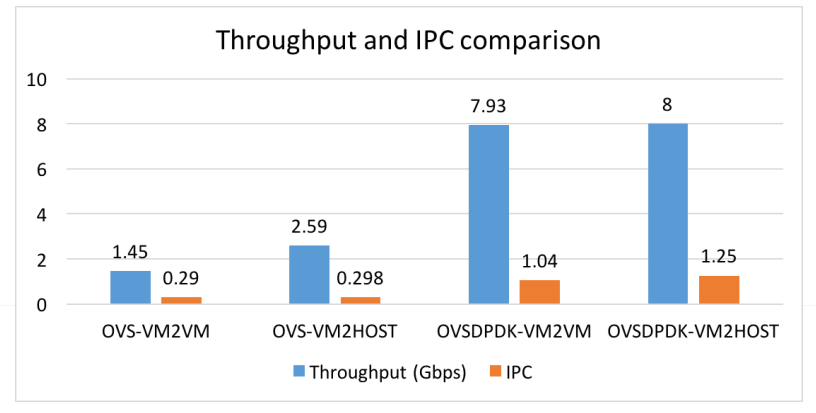
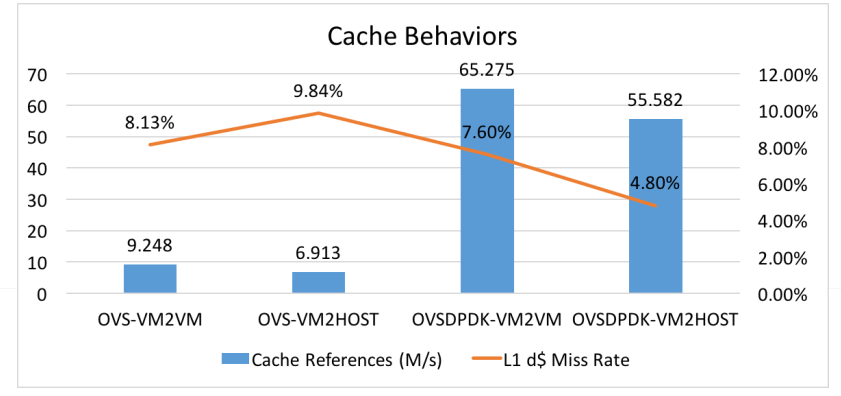
综上所述,DPDK可以极大地提高数据转发的性能和吞吐量,可以大大云环境的网络性能。官方的数据是可以提高10倍性能。
DPDK can improve packet processing performance by up to ten times. DPDK software running on current generation Intel® Xeon® Processor E5-2658 v4, achieves 233 Gbps (347 Mpps) of L3 forwarding at 64-byte packet sizes.
值得注意的是,安装DPDK时要特别注意兼容的kernel版本,ovs版本的对应,否则编译起来会特别suffer。
能看到这里也是真爱呀~关于安装和使用DPDK,有空我会再写一篇相关的blog,看心情~古德拜~